Google has introduced a future feature called “Duplex.” It can make outgoing calls to schedule appointments and it has all the characteristics of real human speech.
Duplex is an example of where our main efforts in AI and natural speech is heading. Commerce wants thier hand on this everywhere. Not just an AI assistant for scheduling, but taking food orders, requesting any type of assistance in the physical world, intake for medical or mental health, ideas are endless. But like any new game changing technology, ethical questions of privacy and security abound.
It’s a new tool from Google that aims to use Artificial intelligence (AI) to “accomplish real-world tasks over the phone” according to Google’s AI researchers and developers. For now, that means very specific tasks like making appointments, but the tech is being developed with an eye on expansion into other areas. Spending billions to create a cool way to make dinner reservations sounds like something Google would do but isn’t a great use of time or money.
Duplex is also more than we saw in a demo and if it ever leaves the lab will be a lot more than we see or hear on our end. There are huge banks of data and the computers to process it involved that aren’t nearly as cool as the final result. But they are essential because making a computer talk and think, in real time, like a person is hard.
Isn’t this just like speech-to-text?
Nope. Not even close. And that’s why it’s a big deal.
Duplex is designed to change the way a computer “talks” on the phone.
The goal for Duplex is to make things sound natural and for Assistant to think on the fly to find an appointment time that works. If Joe says, “Yeah, about that — I don’t have anything open until 10, is that OK?” Assistant needs to understand what Joe is saying, figure out what that means, and think if what Joe is offering will work for you. If you’re busy across town at 10 and it will take 40 minutes to drive to Joe’s Garage, Assistant needs to be able to figure that out and say 11:15 would be good.
Equally important for Google is that Duplex answers and sounds like a person. Google has said it wanted the person on the phone not to know they were talking to a computer, though eventually decided it would be best to inform them. When we talk to people, we talk faster and less formal (read: incoherent babbling from a computer’s point of view) than when we’re talking to Assistant on our phone or the computer at the DMV when we call in. Duplex needs to understand this and recreate it when replying.
Finally, and most impressive, is that Duplex has to understand context. Friday, next Friday, and Friday after next week are all terms you and I understand. Duplex needs to understand them, too. If we talked the same way we type this wouldn’t be an issue, but we umm you know don’t because it sounds just sounds so stuffy yeah it’s not like confusing though we have heard it all our lives and are used to it so no we don’t have problems you know understanding it or nothing like that.
I’ll administer first aid to my editor after typing that while you say it out loud, so you see what this means.
How does Duplex work?
From the user end, it’s as simple as telling Assistant to do something. For now, as mentioned, that something is limited to making appointments so we would say, “Hey Google make me an appointment for an oil change at Joe’s Garage for Tuesday morning,” and (after it reminded us to say please) it would call up Joe’s Garage and set things up, then add it to your calendar.
Continued Conversations use much of the same underlying technology as Duplex.
Pretty nifty. But what happens off camera is even niftier.
Duplex is using what’s called a recurrent neural network. It’s built using Google’s TensorFlow Extended technology. Google trained the network on all those anonymized voicemails and Google Voice conversations you agreed to let it listen to if you opted in with a mix of speech recognition software and the ability to consider the history of the conversation and details like the time of day and location of both parties.
Essentially, an entire network of high-powered computers is crunching data in the cloud and talking through Assistant on your phone or other product that has Assistant on board.
What about security and privacy?
It comes down to one simple thing: do you trust Google. On-device machine intelligence is a real thing, though it’s constrained and relatively new. Google has developed ML Kit to help developers do more of this sort of thing on the device itself, but it’s all a matter of computing power. It takes an incredible amount of computations to make a hair appointment this way, and there’s no way it could be done on your phone or Google Home.
You have to trust Google with your data to use its smart products and Duplex will be no different.
Google needs to tap into much of your personal data to do the special things Assistant can do right now, and Duplex doesn’t change that. What’s new here is that now there is another party involved who didn’t explicitly give Google permission to listen to their conversation.
If/when Duplex becomes an actual consumer product for anyone to use, expect it to be criticized and challenged in courts. And it should be; letting Google decide what’s best for our privacy is like the old adage of two foxes and a chicken deciding what’s for dinner.
When will I have Duplex on my phone?
Expect some big changes to Assistant later this year.
Nobody knows right now. It may never happen. Google gets excited when it can do this sort of fantastic thing and wants to share it with the world. That doesn’t mean it will be successful or ever become a real product.
For now, Duplex is being tested in a closed and supervised environment. If all goes well, an initial experimental release to consumers to make restaurant reservations, schedule hair salon appointments, and get holiday hours over the phone will be coming later this year using Assistant on phones only.
Where can I learn more?
Google is surprisingly open about the tech it is using to create Duplex. You’ll find relevant information at the following websites:
Speech recognition technology has been around for more than half a decade, though the early uses of speech recognition — like voice dialing or desktop dictation — certainly don’t seem as sexy as today’s burgeoning virtual agents or smart home devices.
If you’ve been following the speech recognition technology market for any length of time, you know that a slew of significant players emerged on the scene about six years ago, including Google, Apple, Amazon and Microsoft (in a brief search, I counted 26 U.S.-based companies developing speech recognition technology).
Since that time, the biggest tech trend setters in the world have been picking up speed and setting new benchmarks in a growing field, with Google recently providing open access to its new enterprise-level speech recognition API. While Google certainly seems to have the current edge in the market after substantial investments in machine learning systems over the past couple of years, the tech giant may yet have a potential Achilles’ heel in owning an important segment of the global market — lack of access to China.
The six-year ban on Google in China is a well-known fact, and aside from the very rare lapse in censorship, the block seems relatively immutable for the foreseeable future. With the world’s highest population to date, China also has more mobile users than anywhere in the world, and a majority use voice-to-text capabilities to initiate search queries and navigate their way through the digital landscape.
Google may be missing out on reams of Mandarin audio data, but Baidu hasn’t missed the opportunity to take advantage. As China’s largest search engine, Baidu has collected thousands of hours of voice-based data in Mandarin, which was fed to its latest speech recognition engine Deep Speech 2. The system independently learned how to translate some Mandarin to English (and vice versa) entirely on its own using deep learning algorithms.
The Baidu team that developed Deep Speech 2 was primarily based in its Sunnyvale AI Lab. Impressively, the research scientists involved were not fluent in Mandarin and knew very little of the language. Alibaba and Tencent are two other key players in the Chinese market developing speech recognition technology. Though both use deep learning platforms, neither company has gained the level of publicity and coverage of Baidu’s Deep Speech 2.
Despite its Mandarin prowess, Deep Speech 2 wasn’t originally trained to understand Chinese at all. “We developed the system in English, but because it’s all deep learning-based it mostly depends on data, so we were able to pretty quickly replace it with Mandarin data and train up a very strong Mandarin engine,” stated Dr. Adam Coates, director of Baidu USA’s AI Lab.
The system is capable of “hybrid speech,” something that many Mandarin speakers use when they combine English and Mandarin.
When Deep Speech 2 was first released in December 2015, Andrew Ng, the chief scientist at Baidu, described Deep Speech 2’s test run as surpassing Google Speech API, wit.ai, Microsoft’s Bing Speech, and Apple’s Dictation by more than 10 percent in word error rate.
According to Baidu, as of February of this year, Deep Speech 2’s most recently published error rate is at 3.7 percent for short phrases, while Google has a stated 8 percent word error rate as of about one year ago (to its credit, Google did reduce its error rate by 15 percent over the course of a year). Coates called Deep Speech 2’s ability to transcribe some speech “basically superhuman,” able to translate short queries more accurately than a native Mandarin Chinese speaker.
In addition, the system is capable of “hybrid speech,” something that many Mandarin speakers use when they combine English and Mandarin. “Because the system is entirely data-driven, it actually learns to do hybrid transcription on its own,” said Coates. This is a feature that could allow Baidu’s system to transition well when applied across languages.
Since Baidu’s initial breakthrough, Google has rebuilt its speech recognition system. The newly introduced Cloud Speech API offers developers the ability to speech-to-text translation into any app. The Cloud Speech API is described as working in a variety of noisy environments, and is able to recognize more than 80 languages and dialects.
Image analysis is another touted advantage that Google is using to help attract attention over similar services offered by Amazon and Microsoft. Baidu released via GitHub back in January 2016 the AI software that powers its Deep Speech 2 system, but has yet to release a similar API platform.
Baidu’s achievements and talented team of researchers seems to have the potential needed to significantly impact the technology.
Baidu is a bit hush-hush about much of its technology in development, and it’s difficult to say what specific advancements they’ve made since their introduction of Deep Speech 2 in December 2015. However, their continued progress and potential impact in the speech recognition market may show itself through the partnerships formed in rolling out its technology through other products and services.
Baidu recently tapped into the smart home market with an announcement of integration with Peel’s smart home platform, which offers a popular voice-based, universal remote app for smartphones and tablets.
Google unveiled a number of new AI-driven products, including Google Home, a voice-activated product that allows users to manage appliances and entertainment systems with voice commands, and which draws on the speech recognition technology in its announced “Google Assistant” (the product is scheduled to be released later this year).
Related Articles
Google opens access to its speech recognition API, going head to head with Nuance
Molson And Google Built A Beer Fridge That Unlocks Via Voice Translation
Microsoft’s Project Oxford Gives Developers Access To Facial, Image And Speech-Recognition APIs
In my recent interview with Coates, he also expressed Baidu’s intense interest and behind-the-scenes exploration of developing all manner of AI assistants; perhaps introduction of the “Baidu Assistant” is on the horizon.
Google has some of the best scientists worldwide and a massive technology budget, often putting them ahead of the curve. But Baidu’s achievements and talented team of researchers seems to have the potential needed to significantly impact the technology and gain a foothold in the lucrative Chinese voice market.
That being said, Google did take a minority stake last year in the Chinese-based startup Mobvoi, which is focused on voice recognition technology for mobile devices. With its speech recognition technology well under way, perhaps Google will find inroads that allow it to bypass other U.S.- and Chinese-based players and access the gigantic Chinese market after all.
Tesla’s patent strategy opens the road to sustainability for transport and for itself
If you want to print something a few inches tall, extruded plastic is a good medium. But when you need something at the nanometer scale, DNA is a better bet — but who has the time to design and assemble it base by base? New research lets would-be DNA origami masters design the shape — while an algorithm determines where to put our friends A, T, G, and C.
DNA’s structure doesn’t have to be just a double helix: by fiddling with the order of bases or substituting other molecules, the strand can be cause to make a hard right turn, or curve around in one direction or another — and with enough foresight, a single strand can make enough twists and convolutions that it forms a useful geometric structure.
These structures can be used to deliver drugs, encapsulate tools like CRISPR-Cas9 gene editing elements, or even store information.The problem has been that designing, say, a dodecahedron is a tremendously complicated task, and few have the expertise to assemble such a complex molecule, composed of thousands of base pairs, by hand. That’s what researchers at MIT, Arizona State University, and Baylor University aimed to change, and their success is detailed today in the journal Science.
“The paper turns the problem around from one in which an expert designs the DNA needed to synthesize the object, to one in which the object itself is the starting point, with the DNA sequences that are needed automatically defined by the algorithm,” said MIT’s Mark Bathe in a press release.
Basically, all the user needs to do is provide a 3D shape with a closed surface. It could be a polyhedron, something more round, like a torus, or less symmetrical, like a teardrop. As long as it is designed within certain specifications, once you hand it off to the computer, your work is done.
The algorithm created by the researchers determines the exact order of bases needed to provide the “scaffold,” the single strand of DNA that will bend and twist around itself to produce the shape. It even has a cool name: DAEDALUS. (DNA Origami Sequence Design Algorithm for User-defined Structures — not an exact match, but we’ll forgive them.)
It works like a charm for all kinds of shapes — they checked, of course, using 3D single-particle cryo-electron microscopy, obviously:
The uses in medicine and gene editing are obvious, but the researchers hope that this sudden and drastic increase in the technology’s accessibility will lead to uses being pondered beyond those fields.
DNA storage, for instance, is potentially made far more convenient by this. A unique structure could be created using the algorithm, with portions dedicated to encoded binary data — basically it would be a nanoscale ROM disk made of DNA. How cool is that?
“Our hope is that this automation significantly broadens participation of others in the use of this powerful molecular design paradigm,” said Bathe.
From IBM White Paper: The digital economy has forever changed how consumers, businesses, and employees interact. As your organization’s strategy shifts to embrace this new market, consider these facts: Mobile, web, and cloud technologies are enabling new kinds of business models where innovative new services can be created in a matter of hours from a palette of easy-to-consume APIs. In this API-driven world, organizations can both monetize the value of their corporate data and enrich the existing user experience with third-party APIs.
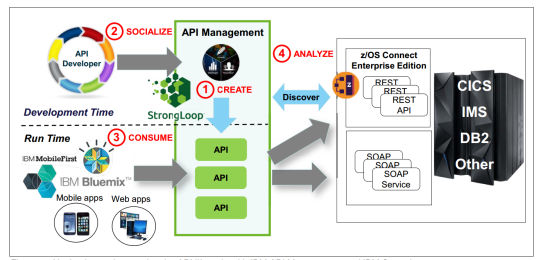
IBM’s Vision of the API Economy
This offers more personalized, concierge-style services. IBM z Systems platforms have a central role to play in the API economy, hosting the most critical and valuable business services and data in the enterprise. New technologies have recently been introduced that make the mainframe fully conversant with REST APIs, putting z Systems platforms at the heart of the API economy. Now, contemporary mobile, digital and cloud applications can directly and securely use z Systems business applications as an equal.
Create (Capability 1):
APIs are imported, discovered, or adapted from existing services and then industrialized. z/OS Connect Enterprise Edition standards-based API definitions enable API Management to import z Systems services automatically. After they are created, the API definitions are hardened
Socialize (Capability 2):
A major benefit of the API economy is to unlock the innovative potential of a multitude of developers. API Management provides a Developer Portal where communities can register, explore, and discover APIs in an intuitive, self-service way. This requirement is both within and increasingly beyond the boundaries of the enterprise
Consume (Capability 3):
After the developers have signed up to access a set of APIs, their credentials and agreed entitlement are enforced through a security gateway that shapes and routes the traffic of their requests to the appropriate end-point service.
Analyze (Capability 4):
One of the most critical factors in establishing a business model based on APIs is understanding who is calling which services, how frequently, and from where. API Management offers a comprehensive analytics service to enable API providers to refine and enhance their underlying business services.
The application programming interface (API) has been a key part of software development for decades as a way to develop for a specific platform, such as Microsoft Windows. More recently, newer platform providers, from Salesforce to Facebook and Google, have offered APIs that help the developer and have, in effect, created a developer dependency on these platforms.Now, a new breed of third-party APIs are offering capabilities that free developers from lock-in to any particular platform and allow them to more efficiently bring their applications to market.
The monolithic infrastructure and applications that have powered businesses over the past few decades are giving way to distributed and modular alternatives. These rely on small, independent and reusable microservices that can be assembled relatively easily into more complex applications. As a result, developers can focus on their own unique functionality and surround it with fully functional, distributed processes developed by other specialists, which they access through APIs.
Faster, cheaper, smarter
Developers realize that much of the functionality they need to build into an app is redundant to what many other companies are toiling over. They’ve learned not to expend precious resources on reinventing the wheel but instead to rely on APIs from the larger platforms, such as Salesforce, Amazon and, more recently, specialized developers. We’re still in the early innings of this shift to third-party APIs, but a number of promising examples illustrate how developers can turn to companies such as Stripe and Plaid for payment connectivity, Twilio for telephony, Factual for location-based data and Algolia for site search.
Indeed, the area is booming. On last check, ProgrammableWeb was providing searchable access to almost 15,000 APIs, with more being added on a daily basis. Developers can incorporate these APIs into their software projects and get to market much more quickly than going it alone.
While getting to market more quickly at a lower cost is a huge advantage, there is an even more important advantage: Companies that focus on their core capabilities develop differentiated functionality, their “secret sauce,” at higher velocity.
The benefits for the rest of the software development ecosystem are profound.
Another advantage is third-party APIs are often flat-out better. They work better and provide more flexibility than APIs that are built internally. Companies often underestimate the amount of work that goes into building and maintaining the functionality that they can now get as a third-party API. Finally, third-party API developers have more volume and access to a larger data set that creates network effects.
These network effects can manifest themselves in everything from better pricing to superior SLA’s to using AI to mine best practices and patterns across the data. For example, Menlo’s portfolio company Signifyd offers fraud analysis as an API. They aggregate retail transactions across hundreds of companies, which allows them to understand a breadth of fraud markers better than any individual customer could.
A new breed of software companies
Releasing software as an API allows those companies to pursue a number of different adoption routes. Rather than trying to sell specific industry verticals or use cases, often the customer is a developer, leading to an extremely low-friction sales process. The revenue model is almost always recurring, which leads to an inherently scalable business model as the end customers’ usage increases. While the ecosystem of API-based companies is early in its evolution, we believe the attributes of these companies will combine to create ultimately more capital-efficient and profitable business models.
This opportunity is not limited to new upstarts. Existing developers may have the opportunity to expose their own unique functionality as an API, morphing their product from application to platform. Some outstanding companies have built API businesses that match or exceed their original focus: Salesforce reportedly generates 50 percent of its revenues through APIs, eBay nearly 60 percent and Expedia a whopping 90 percent.
The model is attractive to entrepreneurs and investors. Rather than trying to create the next hot app and having to invest heavily in marketing and distribution before validating scalable demand, it may make more sense to build a bounded set of functionality and become an arms merchant for other developers.
The API model creates a compelling route to market that if successful can scale capital efficiently and gain a network effect over time. Currently, there are 9 million developers working on private APIs; as that talent sees the opportunity to create companies versus functionalities, we may see a significant shift to public API development (where there are currently only 1.2 million developers).
Rethinking the value chain
In the past, the biggest companies were those closest to the data (e.g. a system of record), able to impose a tax, or lock-in to their platform. In the API economy, the biggest companies may be the ones that aggregate the most data smartly and open it up to others.
This enables new types of competitive barriers, as in Twilio’s ability to negotiate volume discounts from carriers that no individual developer could obtain, or the volume pricing that Stripe enjoys by pooling payments across many developers. Companies like Usermind (a Menlo Ventures portfolio company) show great promise in allowing enterprises to move beyond their single-application silos by creating workflows and simplifying the API connections between their existing SaaS applications.
While the ecosystem for API startups is attractive today, we believe it will only become stronger. Over the last five years there’s been a broadening of interest in enterprise-oriented technologies like SaaS, big data, microservices and AI. APIs are the nexus of all four of those areas.
As the world of enterprise software development further embraces third-party APIs, we expect to see a number of large companies emerge. The low-touch sales model, recurring revenue and lack of customer concentration lead to a very attractive business model. In addition, the benefits for the rest of the software development ecosystem are profound, as app developers can focus on delivering the unique functionality of their app and more quickly and less expensively deliver that ever-important initial product.
A Qubit is a unit of quantum information—the quantum analogue of the classical bit. A qubit is a two-state quantum-mechanical system, such as the polarization of a single photon: here the two states are vertical polarization and horizontal polarization. Properties of qubits are what make quantum computing so different. The freaky quantum reality of superposition and entanglement will really increase computing possibilities in a huge way. I always thought that two possible realities that coexist until someone measures the state was too weird to be of applicable use in some machine or invention .The act of observing the state that finally forces only one possible reality to exist is supernatural to my grounded physical based mind. I always expected that Schrodinger’s cat thought experiment was just for theoretical physics and particle research. Applying these properties to actually make a powerful computing device is such an exciting and incredible feat.
Quantum information is the physics of knowledge. To be more specific, the field of quantum information studies the implications that quantum mechanics has on the fundamental nature of information. By studying this relationship between quantum theory and information, it is possible to design a new type of computer—a quantum computer. A largescale, working quantum computer—the kind of quantum computer some scientists think we might see in 50 years—would be capable of performing some tasks impossibly quickly.
To date, the two most promising uses for such a device are quantum search and quantum factoring. To understand the power of a quantum search, consider classically searching a phonebook for the name which matches a particular phone number. If the phonebook has 10,000 entries, on average you’ll need to look through about half of them—5,000 entries—before you get lucky. A quantum search algorithm only needs to guess 100 times. With 5,000 guesses a quantum computer could search through a phonebook with 25 million names.
Although quantum search is impressive, quantum factoring algorithms pose a legitimate, considerable threat to security. This is because the most common form of Internet security,public key cryptography, relies on certain math problems (like factoring numbers that are hundreds of digits long) being effectively impossible to solve. Quantum algorithms can perform this task exponentially faster than the best known classical strategies, rendering some forms of modern cryptography powerless to stop a quantum codebreaker.
Quantum computers are fundamentally different from classical computers because the physics of quantum information is also the physics of possibility. Classical computer memories are constrained to exist at any given time as a simple list of zeros and ones. In contrast, in a single quantum memory many such combinations—even all possible lists of zeros and ones—can all exist simultaneously. During a quantum algorithm, this symphony of possibilities split and merge, eventually coalescing around a single solution. The complexity of these large quantum states made of multiple possibilities make a complete description of quantum search or factoring a daunting task.
Background On Quantum Stuff
Single qubits. The quantum bit, or qubit, is the simplest unit of quantum information. We look at how single qubits are described, how they are measured, how they change, and the classical assumptions about reality that they force us to abandon.
Pairs of qubits. The second section deals with two-qubit systems, and more importantly, describes what two-qubit systems make possible: entanglement. The crown jewel of quantum mechanics, the phenomenon of entanglement is inextricably bound to the power of quantum computers.
Quantum physics 101. The first two sections will focus on the question of how qubits work, avoiding the related question of why they work they way they do. Here we take a crash course in qualitative quantum theory, doing our best to get a look at the man behind the curtain. The only prerequisites for this course are a little courage and a healthy willingness to ignore common sense.
How can you get more and more out of less and less? The smaller computers get, the more powerful they seem to become: there’s more number-crunching ability in a 21st-century cellphone than you’d have found in a room-sized, military computer 50 years ago. Yet, despite such amazing advances, there are still plenty of complex problems that are beyond the reach of even the world’s most powerful computers—and there’s no guarantee we’ll ever be able to tackle them. One problem is that the basic switching and memory units of computers, known as transistors, are now approaching the point where they’ll soon be as small as individual atoms. If we want computers that are smaller and more powerful than today’s, we’ll soon need to do our computing in a radically different way. Entering the realm of atoms opens up powerful new possibilities in the shape of quantum computing, with processors that could work millions of times faster than the ones we use today. Sounds amazing, but the trouble is that quantum computing is hugely more complex than traditional computing and operates in the Alice in Wonderland world of quantum physics, where the “classical,” sensible, everyday laws of physics no longer apply. What is quantum computing and how does it work? Let’s take a closer look!
Photo: Quantum computing means storing and processing information using individual atoms, ions, electrons, or photons. On the plus side, this opens up the possibility of faster computers, but the drawback is the greater complexity of designing computers that can operate in the weird world of quantum physics. Photo courtesy of US Department of Energy.
What is conventional computing?
You probably think of a computer as a neat little gadget that sits on your lap and lets you send emails, shop online, chat to your friends, or play games—but it’s much more and much lessthan that. It’s more, because it’s a completely general-purpose machine: you can make it do virtually anything you like. It’s less, because inside it’s little more than an extremely basiccalculator, following a prearranged set of instructions called a program. Like the Wizard of Oz, the amazing things you see in front of you conceal some pretty mundane stuff under the covers.
Conventional computers have two tricks that they do really well: they can store numbers in memory and they can process stored numbers with simple mathematical operations (like add and subtract). They can do more complex things by stringing together the simple operations into a series called an algorithm (multiplying can be done as a series of additions, for example). Both of a computer’s key tricks—storage and processing—are accomplished using switches called transistors, which are like microscopic versions of the switches you have on your wall for turning on and off the lights. A transistor can either be on or off, just as a light can either be lit or unlit. If it’s on, we can use a transistor to store a number one (1); if it’s off, it stores a number zero (0). Long strings of ones and zeros can be used to store any number, letter, or symbol using a code based on binary (so computers store an upper-case letter A as 1000001 and a lower-case one as 01100001). Each of the zeros or ones is called a binary digit (or bit) and, with a string of eight bits, you can store 255 different characters (such as A-Z, a-z, 0-9, and most common symbols). Computers calculate by using circuits called logic gates, which are made from a number of transistors connected together. Logic gates compare patterns of bits, stored in temporary memories called registers, and then turn them into new patterns of bits—and that’s the computer equivalent of what our human brains would call addition, subtraction, or multiplication. In physical terms, the algorithm that performs a particular calculation takes the form of an electronic circuit made from a number of logic gates, with the output from one gate feeding in as the input to the next.
Photo: This is what one transistor from a typical radio circuit board looks like. In computers, the transistors are much smaller than this and millions of them are packaged together onto microchips.
The trouble with conventional computers is that they depend on conventional transistors. This might not sound like a problem if you go by the amazing progress made in electronics over the last few decades. When the transistor was invented, back in 1947, the switch it replaced (which was called the vacuum tube) was about as big as one of your thumbs. Now, a state-of-the-art microprocessor (single-chip computer) packs hundreds of millions (and up to two billion) transistors onto a chip of silicon the size of your fingernail! Chips like these, which are calledintegrated circuits, are an incredible feat of miniaturization. Back in the 1960s, Intel co-founder Gordon Moore realized that the power of computers doubles roughly 18 months—and it’s been doing so ever since. This apparently unshakeable trend is known as Moore’s Law.
Photo: This memory chip from a typical USB stick contains an integrated circuit that can store 512 megabytes of data. That’s roughly 500 million characters (536,870,912 to be exact), each of which needs eight binary digits—so we’re talking about 4 billion (4,000 million) transistors in all (4,294,967,296 if you’re being picky) packed into an area the size of a postage stamp!
It sounds amazing, and it is, but it misses the point. The more information you need to store, the more binary ones and zeros—and transistors—you need to do it. Since most conventional computers can only do one thing at a time, the more complex the problem you want them to solve, the more steps they’ll need to take and the longer they’ll need to do it. Some computing problems are so complex that they need more computing power and time than any modern machine could reasonably supply; computer scientists call those intractableproblems.
As Moore’s Law advances, so the number of intractable problems diminishes: computers get more powerful and we can do more with them. The trouble is, transistors are just about as small as we can make them: we’re getting to the point where the laws of physics seem likely to put a stop to Moore’s Law. Unfortunately, there are still hugely difficult computing problems we can’t tackle because even the most powerful computers find them intractable. That’s one of the reasons why people are now getting interested in quantum computing.
What is quantum computing?
Quantum theory is the branch of physics that deals with the world of atoms and the smaller (subatomic) particles inside them. You might think atoms behave the same way as everything else in the world, in their own tiny little way—but that’s not true: on the atomic scale, the rules change and the “classical” laws of physics we take for granted in our everyday world no longer automatically apply. As Richard P. Feynman, one of the greatest physicists of the 20th century, once put it: “Things on a very small scale behave like nothing you have any direct experience about… or like anything that you have ever seen.” (Six Easy Pieces, p116.)
If you’ve studied light, you may already know a bit about quantum theory. You might know that a beam of light sometimes behaves as though it’s made up of particles (like a steady stream of cannonballs), and sometimes as though it’s waves of energy rippling through space (a bit like waves on the sea). That’s called wave-particle duality and it’s one of the ideas that comes to us from quantum theory. It’s hard to grasp that something can be two things at once—a particle and a wave—because it’s totally alien to our everyday experience: a car is not simultaneously a bicycle and a bus. In quantum theory, however, that’s just the kind of crazy thing that can happen. The most striking example of this is the baffling riddle known asSchrödinger’s cat. Briefly, in the weird world of quantum theory, we can imagine a situation where something like a cat could be alive and dead at the same time!
What does all this have to do with computers? Suppose we keep on pushing Moore’s Law—keep on making transistors smaller until they get to the point where they obey not the ordinary laws of physics (like old-style transistors) but the more bizarre laws of quantum mechanics. The question is whether computers designed this way can do things our conventional computers can’t. If we can predict mathematically that they might be able to, can we actually make them work like that in practice?
People have been asking those questions for several decades. Among the first were IBM research physicists Rolf Landauer and Charles H. Bennett. Landauer opened the door for quantum computing in the 1960s when he proposed that information is a physical entity that could be manipulated according to the laws of physics. One important consequence of this is that computers waste energy manipulating the bits inside them (which is why computers use so much energy and get so hot, even though they appear to be doing not very much at all). In the 1970s, building on Landauer’s work, Bennett showed how a computer could circumvent this problem by working in a “reversible” way, implying that a quantum computer could carry out massively complex computations without using massive amounts of energy. In 1981, physicist Paul Benioff from Argonne National Laboratory tried to envisage a basic machine that would work in a similar way to an ordinary computer but according to the principles of quantum physics. The following year, Richard Feynman sketched out roughly how a machine using quantum principles could carry out basic computations. A few years later, Oxford University’s David Deutsch (one of the leading lights in quantum computing) outlined the theoretical basis of a quantum computer in more detail. How did these great scientists imagine that quantum computers might work?
Quantum + computing = quantum computing
The key features of an ordinary computer—bits, registers, logic gates, algorithms, and so on—have analogous features in a quantum computer. Instead of bits, a quantum computer has quantum bits or qubits, which work in a particularly intriguing way. Where a bit can store either a zero or a 1, a qubit can store a zero, a one, both zero and one, or an infinite number of values in between—and be in multiple states (store multiple values) at the same time! If that sounds confusing, think back to light being a particle and a wave at the same time, Schrödinger’s cat being alive and dead, or a car being a bicycle and a bus. A gentler way to think of the numbers qubits store is through the physics concept of superposition (where two waves add to make a third one that contains both of the originals). If you blow on something like a flute, the pipe fills up with a standing wave: a wave made up of a fundamental frequency (the basic note you’re playing) and lots of overtones or harmonics (higher-frequency multiples of the fundamental). The wave inside the pipe contains all these waves simultaneously: they’re added together to make a combined wave that includes them all. Qubits use superposition to represent multiple states (multiple numeric values) simultaneously in a similar way.
Just as a quantum computer can store multiple numbers at once, so it can process them simultaneously. Instead of working in serial (doing a series of things one at a time in a sequence), it can work in parallel (doing multiple things at the same time). Only when you try to find out what state it’s actually in at any given moment (by measuring it, in other words) does it “collapse” into one of its possible states—and that gives you the answer to your problem. Estimates suggest a quantum computer’s ability to work in parallel would make it millions of times faster than any conventional computer… if only we could build it! So how would we do that?
What would a quantum computer be like in reality?
In reality, qubits would have to be stored by atoms, ions (atoms with too many or too few electrons) or even smaller things such as electrons and photons (energy packets), so a quantum computer would be almost like a table-top version of the kind of particle physics experiments they do at Fermilab or CERN! Now you wouldn’t be racing particles round giant loops and smashing them together, but you would need mechanisms for containing atoms, ions, or subatomic particles, for putting them into certain states (so you can store information), knocking them into other states (so you can make them process information), and figuring out what their states are after particular operations have been performed.
Photo: A single atom can be trapped in an optical cavity—the space between mirrors—and controlled by precise pulses from laser beams.
In practice, there are lots of possible ways of containing atoms and changing their states using laser beams, electromagnetic fields, radio waves, and an assortment of other techniques. One method is to make qubits using quantum dots, which arenanoscopically tiny particles of semiconductors inside which individual charge carriers, electrons and holes (missing electrons), can be controlled. Another method makes qubits from what are called ion traps: you add or take away electrons from an atom to make an ion, hold it steady in a kind of laser spotlight (so it’s locked in place like a nanoscopic rabbit dancing in a very bright headlight), and then flip it into different states with laser pulses. In another technique, the qubits are photons inside optical cavities (spaces between extremely tiny mirrors). Don’t worry if you don’t understand; not many people do! Since the entire field of quantum computing is still largely abstract and theoretical, the only thing we really need to know is that qubits are stored by atoms or other quantum-scale particles that can exist in different states and be switched between them.
Photo: Quantum dots are probably best known as colorful nanoscale crystals, but they can also be used as qubits in quantum computers). Photo courtesy of Argonne National Laboratory.
What can quantum computers do that ordinary computers can’t?
Although people often assume that quantum computers must automatically be better than conventional ones, that’s by no means certain. So far, just about the only thing we know for certain that a quantum computer could do better than a normal one is factorisation: finding two unknown prime numbers that, when multiplied together, give a third, known number. In 1994, while working at Bell Laboratories, mathematician Peter Shor demonstrated an algorithm that a quantum computer could follow to find the “prime factors” of a large number, which would speed up the problem enormously. Shor’s algorithm really excited interest in quantum computing because virtually every modern computer (and every secure, online shopping and banking website) uses public-key encryption technology based on the virtualimpossibility of finding prime factors quickly (it is, in other words, essentially an “intractable” computer problem). If quantum computers could indeed factor large numbers quickly, today’s online security could be rendered obsolete at a stroke.
Does that mean quantum computers are better than conventional ones? Not exactly. Apart from Shor’s algorithm, and a search method called Grover’s algorithm, hardly any other algorithms have been discovered that would be better performed by quantum methods. Given enough time and computing power, conventional computers should still be able to solve any problem that quantum computers could solve, eventually. In other words, it remains to be proven that quantum computers are generally superior to conventional ones, especially given the difficulties of actually building them. Who knows how conventional computers might advance in the next 50 years, potentially making the idea of quantum computers irrelevant—and even absurd.
How far off are quantum computers?
Three decades after they were first proposed, quantum computers remain largely theoretical. Even so, there’s been some encouraging progress toward realizing a quantum machine. There were two impressive breakthroughs in 2000. First, Isaac Chuang (now an MIT professor, but then working at IBM’s Almaden Research Center) used five fluorine atoms to make a crude, five-qubit quantum computer. The same year, researchers at Los Alamos National Laboratory figured out how to make a seven-qubit machine using a drop of liquid. Five years later, researchers at the University of Innsbruck added an extra qubit and produced the first quantum computer that could manipulate a qubyte (eight qubits). Over the next few years, researchers announced more ambitious experiments, adding progressively greater numbers of qubits. By 2011, a pioneering Canadian company called D-Wave Systems announced inNature that it had produced a 128-qubit machine. Thee years later, Google announced that it was hiring a team of academics (including University of California at Santa Barbara physicist John Martinis) to develop its own quantum computers based on D-Wave’s approach. In March 2015, the Google team announced they were “a step closer to quantum computation,” having developed a new way for qubits to detect and protect against errors. Even so, it’s very early days for the whole field—and most researchers agree that we’re unlikely to see practical quantum computers appearing for many years—perhaps even decades.
Oxford Quantum: A handy collection of quantum computing resources from Oxford University’s Clarendon Laboratory.
The Quantised World: A great introduction to quantum theory from the educational section of the Nobel Prize website. Includes links to biographies of the various Nobel Prize winning physicists who laid the foundations of quantum theory in the early part of the 20th century.
Books
Introductions to quantum theory
Six Easy Pieces by Richard Feynman. Basic Books, 2011. Chapter 6 is a short and very concise introduction, focusing on the famous double-slit experiment that confirms things can be particles and waves at the same time.
Mr Tompkins in Paperback by George Gamov. Cambridge University Press, 1993. A modern reissue of the classic introduction to quantum theory from one of its 20th-century pioneers.
Introductions to quantum computing
A Shortcut Through Time: The Path to the Quantum Computer by George Johnson. Random House, 2004. An easy-to-follow, popular-science-style guide covering the basics of quantum computing (similar in scope to this article but in much more detail). Also covers related fields such as quantum cryptography. This is the best place to start for an absolute beginner who doesn’t want to get bogged down in math.
The Fabric of Reality by David Deutsch. Penguin, 2011. From one of the pioneers of quantum computing, a look at the broad implications of quantum theory, including a couple of chapters (6 and 9) that address quantum computing.
More detailed
Quantum Computation and Quantum Information by Michael A. Nielsen and Isaac L. Chuang. Cambridge University Press, 2011. The definitive academic textbook by two quantum computing pioneers.
Articles
Google’s Quantum Dream Machine by Tom Simonite. MIT Technology Review. December 18, 2015. Can physicist John Martinis help Google deliver the “holy grail” of quantum computing?
D-Wave’s Year of Computing Dangerously by Jeremy Hsu. IEEE Spectrum, Nov 26, 2013. Has D-Wave really cracked quantum computing? Despite some big customer orders, experts remain skeptical that its approach is any better than traditional forms of number crunching.
Quantum computer slips onto chips: BBC News, 4 September 2009. Bristol University researchers attempt to build a quantum chip that can compute Shor’s algorithm.
The Fundamental Limits of Computation by Charles H. Bennett and Rolf Landauer, Scientific American, July 1985. Introduces the concept of reversible computation and then explains how quantum computers could work in a reversible way.
Affectiva is a software company that has developed a product named AFFDEX® which delivers real-time insight into unspoken, spontaneous reactions to advertisements, concepts, and other media content. Using advanced facial analysis, Affdex scientifically measures emotional responses unobtrusively, cost effectively, and at scale. Facial coding….more
The Turing test is a test of a machine’s ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human. In the original illustrative example, a human judge engages in natural language conversations with a human and a machine designed to generate performance indistinguishable from that of a human being. The conversation is limited to a text-only channel such as a computer keyboard and screen so that the result is not dependent on the machine’s ability to render words into audio. All participants are separated from one another. If the judge cannot reliably tell the machine from the human, the machine is said to have passed the test. The test does not check the ability to give the correct answer to questions; it checks how closely each answer resembles the answer a human would give.
The test was introduced by Alan Turing in his 1950 paper “Computing Machinery and Intelligence,” which opens with the words: “I propose to consider the question, ‘Can machines think?'” Because “thinking” is difficult to define, Turing chooses to “replace the question by another, which is closely related to it and is expressed in relatively unambiguous words.”Turing’s new question is: “Are there imaginable digital computers which would do well in the imitation game?”This question, Turing believed, is one that can actually be answered. In the remainder of the paper, he argued against all the major objections to the proposition that “machines can think”.
Elisa
S-Voice and Sirus
Emotional data collection and data mining from social media. Emotional reaction predictions (and thus real-time manipulation of ) based on emotional profiles of demographics and analysis of real-time internet experinces Marketing Analysis
Sorry I promise to get back to tech tomorrow, but one more women in tech blog. Being a working mom with a tech career, I have had to deal with so much flack from co-working men with stay home wives or young late twenties early thirties men and women who are single or just getting wed. I even had to deal with an independent single dating grandma. What flack did they give me. Questioning not my work quantity or quality. But why I am working from home so much and/or taking my kids to doctors or going to school functions during the day. Not going to the every other day happy hour or just being so direct and to the point just to be efficient and get ‘er done. So the below article about the Katherine Zaleski apology from my favorite mommy helper service Care.com is a comfort and are issues that need to be talked about!!!
Katharine Zaleski’s Apology Should Inspire Us All to Treat Working Moms Better
She is, deservedly, getting plenty of love and pub this week for being refreshingly self-aware and owning the role she, as a woman, once played in making the workplace inhospitable for working moms.
“For mothers in the workplace, it’s death by a thousand cuts – and sometimes it’s other women holding the knives,” Zaleski wrote for “Fortune,” in a piece in which now-CEO apologizes to the mothers she’s judged or passively held down. “I didn’t realize this – or how horrible I’d been – until five years later, when I gave birth to a daughter of my own.”
And good for Katharine Zaleski for doing something about it, for aspiring to give career-minded working moms a third option – one between “leaning in” and “opting out.” She’s doing this as co-founder and president of PowerToFly, a job-matching platform connecting women with digital and tech jobs they can do remotely.
But it’s not enough for us to simply congratulate Katharine Zaleski.
We must take a hard look at ourselves, and challenge the structures and systems that have led us to the point where working mothers feel like they only have three options. Because gender diversity isn’t a women’s issue, it’s everybody’s issue.
Explaining the vision for PowerToFly, Zaleski writes: “By enabling women to work from home, women could be valued for their productivity and not time spent sitting in an office or at a bar bonding afterwards.”That’s a fantastic start. The next step is one we must all take together.
The day before Zaleski’s “Fortune” piece hit the web, the New York Times published a piece titled“Fewer Women Run Big Companies Than Men Named John.” In fact, for each woman executive at S.&P. 1500 firms, there are four men named John, Robert, William or James.
Let that sink in for a minute.
Helping highly skilled working moms find good digital and tech jobs is fantastic. It will help countless women continue their careers while maintaining a healthy work-life balance. But it’s only the tip of the iceberg.
Distributing female talent to remote roles doesn’t cut to the core of the problem – that organizational culture is not particularly family-friendly and women, who are often the default parent, are disproportionately affected.
We, as business leaders and executives, need to take a long look in the mirror and identify what we can do within our own organizations to prevent women – and all parents – from ever feeling like they only have two choices: never see your child or give up your career aspirations.
Now here’s what I’m challenging you to do, and it’s the simplest step enterprises can take to help the working moms, new dads and all other caregivers in their workforce: Focus on results.
That’s it. Focus on results – not when or where the work gets done, or how many hours are spent in the office. And do it for your entire workforce – not just the moms, or the remote employees.
Do this and your organizational culture will become more family-friendly, more supportive of work-life integration. You’ll be rewarded with more engaged, loyal and productive employees.
So Tell Us: What are your ideas for improving gender diversity in the workplace? How can we take the PowerToFly philosophy of focusing on results and apply it to workplaces everywhere?
Donna Levin is a co-founder and Vice President of Public Policy and CSR for Care.com. In this role, she is dedicated to discovering innovative solutions to the growing global care issue, helping shape local, federal and state matters as they pertain to families.
In today’s male-dominated computer programming industry, it’s easy to forget that a woman — Grace Hopper — helped usher in the computer revolution. During World War II, Hopper left a teaching job at Vassar College to join the Navy Reserve. That’s when she went to Harvard to work on the first programmable computer in the United States: the Mark I.
Women were responsible for programming early computers, and Hopper led the charge. Later in her career, Hopper helped create a common language that computers could understand. It was called common business oriented language, or COBOL — a programming language still used today.
Rear Admiral Hopper went on to become the oldest serving officer in the United States Navy. She died in 1992 at the age of 85.
Joan Clarke’s ingenious work as a codebreaker during WW2 saved countless lives, and her talents were formidable enough to command the respect of some of the greatest minds of the 20th Century, despite the sexism of the time. But while Bletchley Park hero Alan Turing – who was punished by a post-war society where homosexuality was illegal and died at 41 – has been treated more kindly by history, the same cannot yet be said for Clarke. The only woman to work in the nerve centre of the quest to crack German Enigma ciphers, Clarke rose to deputy head of Hut 8, and would be its longest-serving member. She was also Turing’s lifelong friend and confidante and, briefly, his fiancée. Her story has been immortalised by Keira Knightley in The Imitation Game, out in UK cinemas this week.
In 1939, Clarke was recruited into the Government Code and Cypher School (GCCS) by one of her supervisors at Cambridge, where she gained a double first in mathematics, although she was prevented from receiving a full degree, which women were denied until 1948.
As was typical for girls at Bletchley, (and they were universally referred to as girls, not women) Clarke was initially assigned clerical work, and paid just £2 a week – significantly less than her male counterparts. Within a few days, however, her abilities shone through, and an extra table was installed for her in the small room within Hut 8 occupied by Turing and a couple of others.
In order to be paid for her promotion, Clarke needed to be classed as a linguist, as Civil Service bureaucracy had no protocols in place for a senior female cryptanalyst. She would later take great pleasure in filling in forms with the line: “grade: linguist, languages: none”. The navy ciphers decoded by Clarke and her colleagues were much harder to break than other German messages, and largely related to U-boats that were hunting down Allied ships carrying troops and supplies from the US to Europe. Her task was to break these ciphers in real time, one of the most high-pressure jobs at Bletchley, according to Michael Smith, author of several books on the Enigma project. The messages Clarke decoded would result in some military action being taken almost immediately, Mr Smith explains. U-boats would then either be sunk or circumnavigated, saving thousands of lives.Joan Clarke’s work helped avert several German U-boat attacks in the Atlantic.
Because of the secrecy that still surrounds events at Bletchley Park, the full extent of Clarke’s achievements remains unknown. Although she was appointed MBE in 1947 for her work during WW2, Clarke, who died in 1996, never sought the spotlight, and rarely contributed to accounts of the Enigma project. There were a handful of other female codebreakers at Bletchley, notably Margaret Rock, Mavis Lever and Ruth Briggs, but as Kerry Howard – one of the few people to research their roles in GCCS – explains, their contributions are hardly noted anywhere. “Up until now the main focus has been on the male professors who dominated the top level at Bletchley,” she says. In order to find any information on the women involved, you have “to dig much deeper”. “There are a lot of people in this story who should have their place in history,” says Keira Knightley.”Joan is certainly one of them”.
Uber is leaving San Antonio over City Council’s refusal to repeal ride-sharing ordinance
I am a huge fan of the share economy revolution. Technology finally working for the average middle class person. It really cuts out the Big Co. fat cat from the equation. Direct commerce – avatar to avatar (and then we meet when you pick me up in your fuel economy car). What could be cooler? There are so many times I have taken a cab and thought how I was at the mercy of some strange made up cost exchange to some big guy who could tell me I owe him much more than I had in my pocket for the ride at my destination. The metered rides never added up to me, but I was scared and too dependent to barter. If I asked the cabbie “how much would it cost to take me to the airport” I never got a straight answer! So when GPS , Paypal, social media reviewing on smart phones, and some average Jo who had a car all got mixed up, catching rides in cities became fair and safer for me. Uber is awesome and so very “for the people by the people”. So imagine how bummed I am about the below. Having worked and lived in San Antonio, I can only say, “boooooooo to you SA” – sad face.
Mar 5, 2015, 4:00pm CST
Photographer: Andrew Harrer/Bloomberg W. Scott Bailey Reporter/Project Coordinator- San Antonio Business Journal
Re-post
From the San Antonio Business Journal by Andrew Harrer
Uber says it will not be able to operate in the San Antonio city limits once a revised ride-sharing ordinance, approved on March 5, is implemented.
Uber is ready to say adios to San Antonio. The company had threatened to exit the market unless the city repealed a December ordinance affecting ride-sharing companies. On Thursday, City Council instead voted 8-2 to approve a number of changes to the ordinance.
So I asked Uber’s Debbee Hancock if the company is indeed planning to leave San Antonio.
“Yes,” she said. “We will not be able to operate within San Antonio’s city limits when this ordinance is implemented.”
Uber officials have not disclosed a departure date. But Hancock said the “revised ordinance remains one of the most burdensome in the nation.”
She added, “In one vote, the city has destroyed thousands of jobs and eliminated a safe transportation option.”
City leaders said San Antonio had to strike a balance between trying to address Uber’s concerns and protecting public safety.
Yellow Cab San Antonio President John Bouloubasis, who had urged Council members not to bow to political pressure from Uber, said after the Thursday vote that the city had showed “that it cannot be bought or bullied by expensive lobbyists.”
According to this Engadget article, looks like all my MS hating, Minecraft loving friends are grieving today! What could go wrong? Maybe Minecraft will get easier to install. Or maybe it will cost more money? Will the Mac version still be supported and will pocket Minecraft still work on iOS, Androids, and Fire?
I really can feel for the founder/owner of Minecraft. He apparently became so overwhelmed by the massive work it takes to manage a gaming business with such a vocal community. It took over his life. I started a small local web design company and it has nearly killed me. I get it. Not everyone wants to be a slave to their job and their creations. This is the tweet that caused Microsoft and Blizzard (EA) to bid out Persson’s shares. But Microsoft? Wow! Or should I say WoW. I wonder. I understand that the XBOX has changed all views towards Microsoft as the Windows/Office conquer the world with bad software king. But I still know so many hardcore MS haters that wont ever touch a XBOX. I wonder what the reaction will be.
I don’t dislike Microsoft. In fact with out Microsoft, I wouldn’t have the IT career I do. So the kids and I own a XBOX and we also own Minecraft for XBOX. I play the game with my 11 yr old son and 6yr old daughter and their friends. I have created a secure server for them to play remotely in their worlds. Other than the animal killing and noises that are made by these block characters during distress, I love the game and think it is an excellent creative learning tool for my children. We mostly play the game in the house on our Macs, unless we have no Wifi and then we play the pocket version on our 4G tablets or phones. But we play the game on a variety of devices and OS other than XBOX. They include iOS (iPads and Macs), Android (Samsung Galaxy Note tablets and phones, and Amazon-Fire), and Windows (HP, DELL, VIAO laptops & convertibles). Will Microsoft limit that freedom?
Again I do respect Persson’s choice to move on with his life. As explained in a Forbes interview “… FORBES represent Persson’s only interview about the Minecraft deal and his life after. It turns out that the most certain thing this windfall bought him was some heavy soul-searching. The only thing he has learned for sure: He was right to walk away from Minecraft. In explaining his recent decisions, he quotes Leonardo da Vinci: “Art is never finished, only abandoned.””
I just hope that the new owners continue to nurture such a strong and open community and keep the cost down. One of the upsides maybe that there will be more Minecraft merchandise for our kids birthday parties 🙂
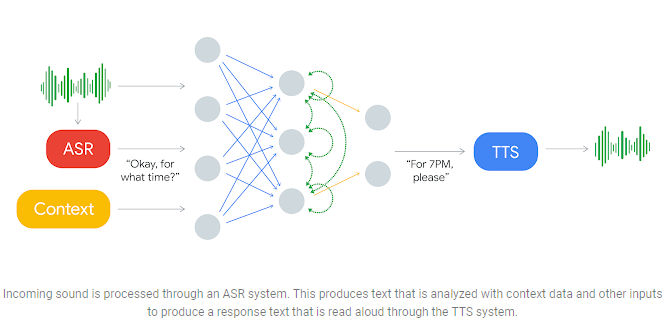

 Continued Conversations use much of the same underlying technology as Duplex.
Continued Conversations use much of the same underlying technology as Duplex. Expect some big changes to Assistant later this year.
Expect some big changes to Assistant later this year.
 If you want to print something a few inches tall, extruded plastic is a good medium. But when you need something at the nanometer scale, DNA is a better bet — but who has the time to design and assemble it base by base? New research lets would-be DNA origami masters design the shape — while an algorithm determines where to put our friends A, T, G, and C.
If you want to print something a few inches tall, extruded plastic is a good medium. But when you need something at the nanometer scale, DNA is a better bet — but who has the time to design and assemble it base by base? New research lets would-be DNA origami masters design the shape — while an algorithm determines where to put our friends A, T, G, and C.

 The application programming interface (API) has been a key part of software development for decades as a way to develop for a specific platform, such as Microsoft Windows. More recently, newer platform providers, from Salesforce to Facebook and Google, have offered APIs that help the developer and have, in effect, created a developer dependency on these platforms.Now, a new breed of third-party APIs are offering capabilities that free developers from lock-in to any particular platform and allow them to more efficiently bring their applications to market.
The application programming interface (API) has been a key part of software development for decades as a way to develop for a specific platform, such as Microsoft Windows. More recently, newer platform providers, from Salesforce to Facebook and Google, have offered APIs that help the developer and have, in effect, created a developer dependency on these platforms.Now, a new breed of third-party APIs are offering capabilities that free developers from lock-in to any particular platform and allow them to more efficiently bring their applications to market. ening of interest in enterprise-oriented technologies like SaaS, big data, microservices and AI. APIs are the nexus of all four of those areas.
ening of interest in enterprise-oriented technologies like SaaS, big data, microservices and AI. APIs are the nexus of all four of those areas.





 conversation is limited to a text-only channel such as a
conversation is limited to a text-only channel such as a 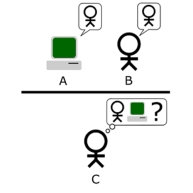 ‘Can machines think?'” Because “thinking” is difficult to define, Turing chooses to “replace the question by another, which is closely related to it and is expressed in relatively unambiguous words.”
‘Can machines think?'” Because “thinking” is difficult to define, Turing chooses to “replace the question by another, which is closely related to it and is expressed in relatively unambiguous words.”




 common business oriented language, or COBOL — a programming language still used today.
common business oriented language, or COBOL — a programming language still used today.








 Maybe Minecraft will get easier to install. Or maybe it will cost more money? Will the Mac version still be supported and will pocket Minecraft still work on iOS, Androids, and Fire?
Maybe Minecraft will get easier to install. Or maybe it will cost more money? Will the Mac version still be supported and will pocket Minecraft still work on iOS, Androids, and Fire?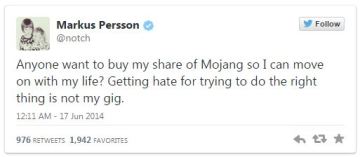 I don’t dislike Microsoft. In fact with out Microsoft, I wouldn’t have the IT career I do. So the kids and I own a XBOX and we also own Minecraft for XBOX. I play the game with my 11 yr old son and 6yr old daughter and their friends. I have created a secure server for them to play remotely in their worlds. Other than the animal killing and noises that are made by these block characters during distress, I love the game and think it is an excellent creative learning tool for my children. We mostly play the game in the house on our Macs, unless we have no Wifi and then we play the pocket version on our 4G tablets or phones. But we play the game on a variety of devices and OS other than XBOX. They include iOS (iPads and Macs), Android (Samsung Galaxy Note tablets and phones, and Amazon-Fire), and Windows (HP, DELL, VIAO laptops & convertibles). Will Microsoft limit that freedom?
I don’t dislike Microsoft. In fact with out Microsoft, I wouldn’t have the IT career I do. So the kids and I own a XBOX and we also own Minecraft for XBOX. I play the game with my 11 yr old son and 6yr old daughter and their friends. I have created a secure server for them to play remotely in their worlds. Other than the animal killing and noises that are made by these block characters during distress, I love the game and think it is an excellent creative learning tool for my children. We mostly play the game in the house on our Macs, unless we have no Wifi and then we play the pocket version on our 4G tablets or phones. But we play the game on a variety of devices and OS other than XBOX. They include iOS (iPads and Macs), Android (Samsung Galaxy Note tablets and phones, and Amazon-Fire), and Windows (HP, DELL, VIAO laptops & convertibles). Will Microsoft limit that freedom?